What the First Foresight Experiment Taught Us About Predicting Clément's Movie Taste

Kleros just ran the distilled human judgement for recommendations end-to-end on the mainnet with real money. Sixteen markets opened, five resolved against a single person's verified ratings, and redemption is now live for everyone who traded.
Distilled human judgement is the idea, written up by Vitalik building on Robin Hanson's futarchy work, that you can use prediction markets to cheaply approximate an expensive, trusted judgement. Pick a person whose call you would trust if they had time to study every case. Run markets that predict what they would conclude. Have them resolve a small random sample. The market becomes a scalable proxy for that person's judgement.
Session 1 ran that experiment with Clément, our CTO, as the judge and movie ratings as the question. The point was to test the full stack, from mint to redeem, before running the same mechanism on things that matter more.
This post walks through what happened: how the markets performed against two baselines, where the math paid out, what we shipped during the experiment, and what comes next. If you traded and want to know whether your positions made money, the worked examples below use real on-chain numbers.
The setup, briefly
Session 1 launched on March 5, 2026, with 16 movies in the parent market and a trading period of around four weeks. The market question for each conditional market was: "If watched, what percentile score would Clément give to the movie?" Clément would not watch all 16. Five were selected: the top three by market estimate, one chosen randomly, and one chosen by Clément himself. The trading period ended on 3rd April.
The top three by market estimate at close were 12 Angry Men (70.67%), Alien (70.12%), and Bacurau (66.64%). The random pick used the hash of Ethereum block 24806735 as the source of randomness, taken modulo 13 to pick from the remaining movies. The result pointed to the first remaining movie in the interface: Judge Dredd. Clément's own choice was Demolition Man, which had finished fifth in the market.
¹Yesterday the trading period of the first Foresight experiment concluded.
— Clément Lesaege (@clesaege) April 4, 2026
The top 3 that I will watch are:
- 12 angry men (70.67%)
- Alien (70.12%)
- Bacurau (66.64%) pic.twitter.com/klIHkeihyp
EthCC POAP holders and humans verified on Proof of Humanity each received $25 in trading credit at the start of the experiment. A smaller group handpicked by Clément received $50. These credits gave participants a way to enter without bringing in fresh capital.
Vitalik retweeted the experiment announcement during the trading window. The author of the essay that named distilled human judgement endorsed the first on-chain implementation of it.
The results
Clément watched the five movies and submitted his percentile ratings via Criticker. Session 1 had 113 participants trading across the 16 markets. Here is how the market estimates compared to his actual ratings, alongside two baselines we tracked for comparison.
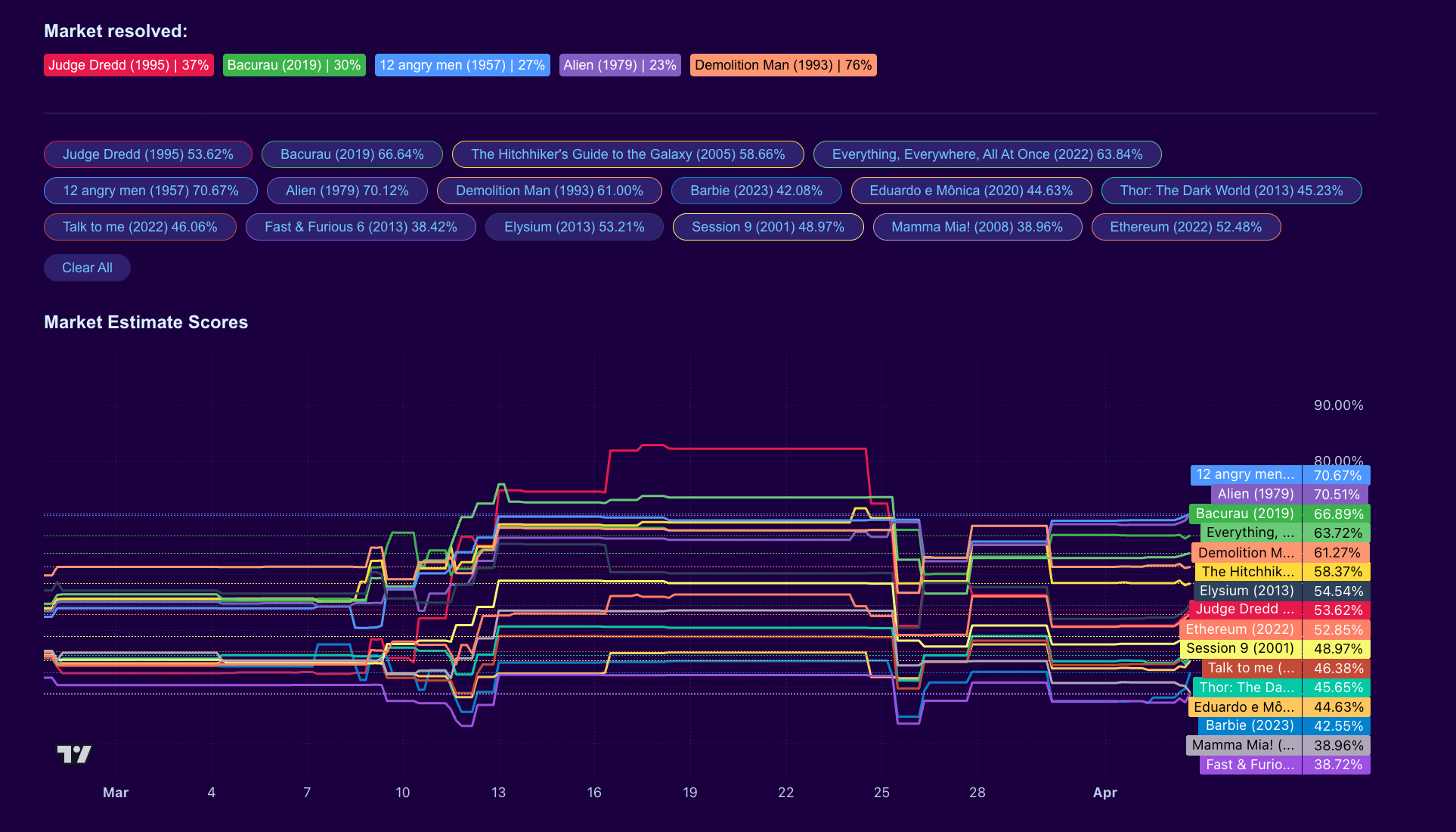
| Movie | Clément's rating | Market | Criticker | Clément + ChatGPT | ChatGPT (no memory) |
|---|---|---|---|---|---|
| 12 Angry Men | 27 | 71 | 79 | 30 | 90 |
| Bacurau | 30 | 67 | 62 | 55 | 83 |
| Alien | 23 | 70 | 86 | 55 | 88 |
| Judge Dredd | 37 | 54 | 24 | 57 | 45 |
| Demolition Man | 76 | 61 | 46 | 61 | 69 |
Average Absolute Error: Market 32, Criticker 38, ChatGPT (no memory) 42, Clément + ChatGPT 19.
Average Absolute Ranking Error: Market 2.4, Criticker 2.4, ChatGPT no memory 2.4, Clément + ChatGPT 0.6.
A few things stand out.
The market beat Criticker. On absolute error, the market came in at 32 versus Criticker's 38. Criticker's score for each movie is not a general consensus rating. It is a personalized prediction generated from Clément's own rating history, matched against users with similar tastes. The market was a better predictor of Clément's actual ratings than Criticker's personalized baseline. That is a real signal, not noise. Traders were picking up something about Clément's taste that Criticker's tailored model missed.
The market lost to Clément + ChatGPT. This is not generic ChatGPT; It is Clément's own instance, with memory of his preferences and rating history, and Clément actively discussed each movie with it and iterated on the prompt rather than taking a single-shot output. With that context, the model produced predictions with an average error of 19 and a ranking error of 0.6, the best of any predictor.
We also tested ChatGPT in temporary mode against the same five movies. Three runs were conducted: two on the current version and one on a smaller reasoning model, using a prompt restricted to public information only (Criticker profile and web search). All three runs landed at an average absolute error of around 42 and a ranking error of 2.4, behind both the market and Criticker on absolute error and tied with them on ranking. Without Clément's rating history loaded in, ChatGPT collapses back toward critical consensus.
That outcome is expected, not a surprise. Clément, combined with an AI tool that has direct access to his taste, should outperform any predictor that relies only on public information about him. Among the public-information predictors (market, Criticker, and generic ChatGPT), the market performed best.
Why the market overestimated
Looking at the table, the market was higher than Clément's actual rating on four out of five movies, with Alien off by nearly 50 points. The bias runs in one direction, which points to something structural rather than random error.
Clément flagged two biases at play:
1. He is more likely to remember, and therefore rate, movies he liked. The market resolved against his Criticker scores, which answers the question, "How would Clément rate this movie compared to all movies he rated?" If the question had been, "How would Clément rate this movie compared to all the movies he has ever watched?" the results would have been closer to the market.
2. He is more likely to watch movies he expects to enjoy. The one movie he picked himself, Demolition Man, came in closest to the market estimate.
Session 2 addresses this directly: the candidate pool consists of movies Clément himself selected to potentially watch. Letting the judge curate the candidate list removes part of the bias that pulled Session 1's market predictions away from his actual ratings.
I'm gonna run a cool futarchy experiment. Suggest me some movies that you think I would like or not like! Reply with:
— Clément Lesaege (@clesaege) June 23, 2025
Like: [Movie Name]
Don't like: [Movie Name]
Demolition Man: the one that stood out
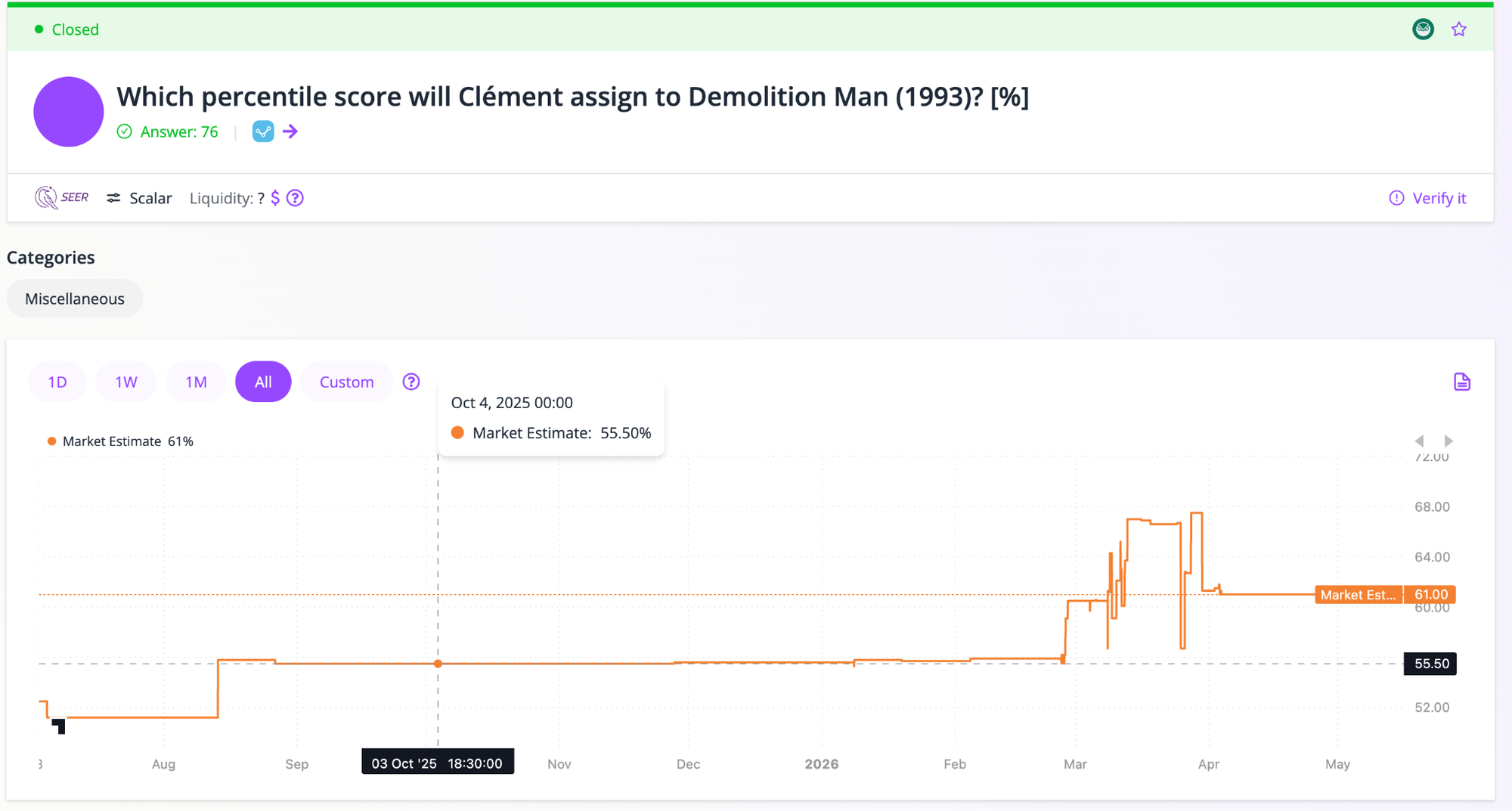
Four of the five movies landed between 23 and 37. Demolition Man broke the pattern at 76. It was the only one Clément clearly enjoyed and the only conditional market where the market estimate moved in the right direction during trading.
It spiked above 67 and closed at 61. The resolution at 76 means anyone who bought UP during that climb was on the right side. The market got the direction right but underestimated how much Clément would enjoy it.
Demolition Man was the only movie in the resolved sample that Clément himself picked. For the one film he chose, the market estimate landed closest to his actual rating.
Clément on Demolition Man:
"It is remarkable how much Demolition Man, a 1993 movie released when I was only one, managed to anticipate about our society. What probably looked like absurd caricature back then now feels uncomfortably plausible."
Here is the math, using the redemption formulas from the Advanced Guide.
Say Alice predicted Demolition Man would score higher than 55, the market estimate when she entered. She buys 10 UP tokens at $0.55 each, for a stake of $5.50. Clément watches the movie and rates it 76. UP tokens redeem at Evaluation ÷ Max = 76 ÷ 100 = $0.76 each.
Alice gets back 10 × $0.76 = $7.60, for a profit of $2.10 (~38%).
What this looks like in your Trade Wallet
If you participated, your positions are now redeemable at foresight.kleros.io. The interface shows each market with its final position value. Clicking Redeem outcome tokens on your Trade Wallet shows the total sDAI you will receive across all positions combined.

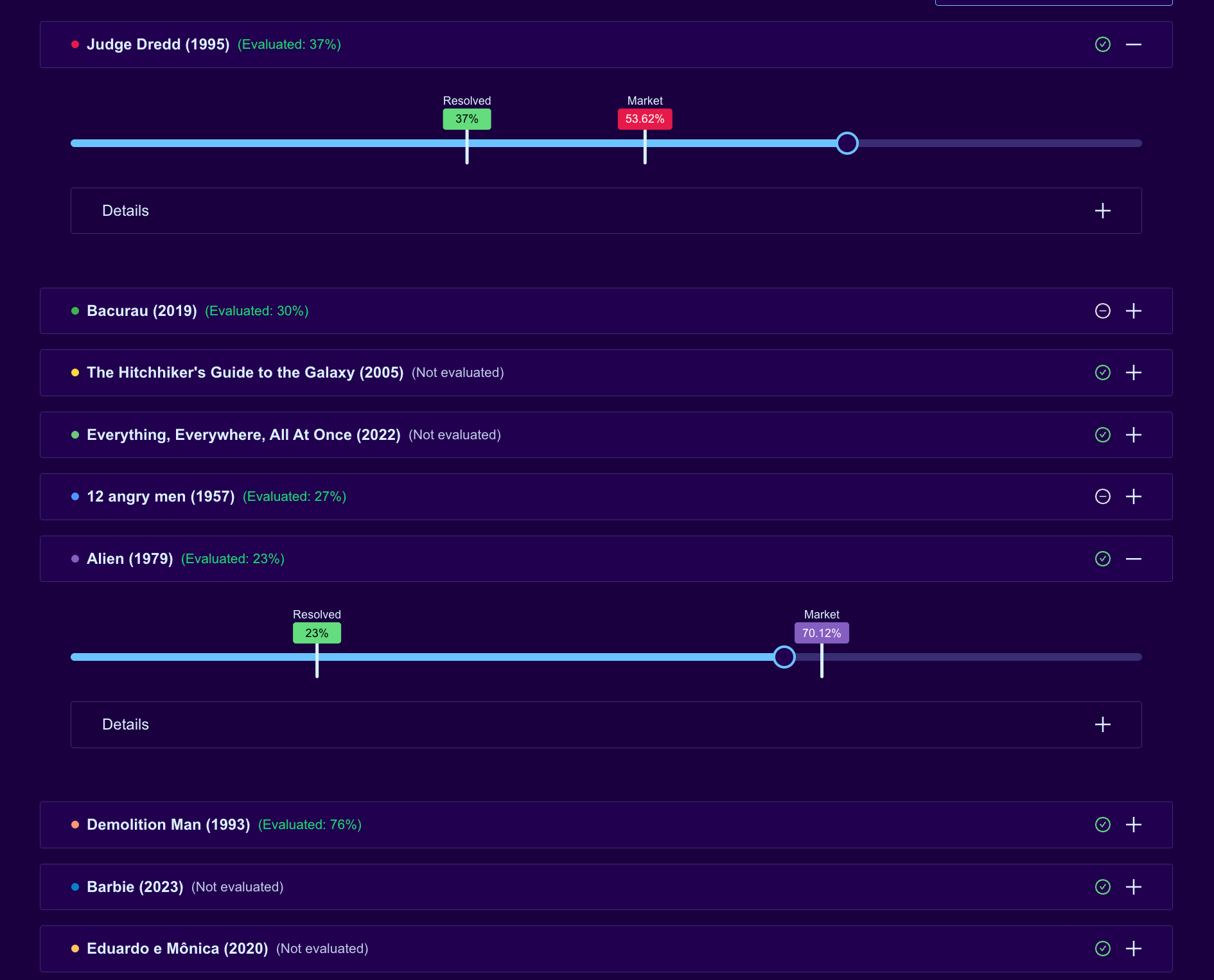
Each evaluated market now displays both pointers on the slider: a green Resolved marker at Clément's actual rating and the Market marker at the closing estimate. For Judge Dredd, the slider shows Resolved at 37% and Market at 53.62%, meaning DOWN positions won. For Alien, Resolved at 23% with Market at 70.12% means a much larger DOWN payout.
Bugs we hit, and what got fixed
No major bugs surfaced during Session 1. A few minor issues came up during the experiment. Participants flagged them in the Telegram channel, and the team shipped fixes in real time. The flow you see today is the cleaned-up version
What we are taking forward
Session 1 was a beta. The point was to test the full flow end-to-end with real money on a low-stakes question. The mechanism worked: parent market selected the movies, conditional markets resolved against Clément's Criticker scores, Reality.eth processed the oracle submissions, and redemption is live. That is the system functioning as it was designed.
What's next
Foresight is moving from a movie experiment to more consequential applications.
You can see what's live and what's queued at foresight.kleros.io.
Round 2 of the movie experiment is launching. This time, Clément himself selected the candidate pool, which addresses the selection bias that surfaced in Session 1. The link to participate is https://movies-r2.foresight.kleros.io/.
The other directions we are actively working on:
- Grant allocation based on KPIs: using futarchy to decide which proposals get funded, conditional on what each is predicted to deliver
- Risk pricing for DeFi: aggregating crowd judgement on the risk profile of protocols, vaults, or positions
If you held positions in Session 1 and have not redeemed yet, the Redeem outcome tokens button is live on your Trade Wallet. If you participated and noticed bugs we did not catch, the Telegram group is the fastest way to flag them.
Thanks to everyone who traded, including the EthCC participants who used their credits to push the experiment to scale.

